V rámci refaktoringu jednoho staršího projektu řešíme přepis a napojení interfacu na naše standardizované REST API, které musí poskytovat interně stránkování pomocí cursoru, aby šlo napojit na náš interface GraphQL.
Předpokládám, že vysvětlovat, co je stránkování pomocí cursoru nemusim, nějaké základní vysvětlení a jeho výhody již napsali chytřejší lidé, než jsem já, a tak stačí mrknout třeba na blog vývojářů slacku.
Obsahem tohoto článku bude, jaká všechna úskalí mě potkala, když jsem se do implementace vrhnul (a také jsem byl k sepsání donucen kolegou 😉, kterého implementace cursor based pagination bude čekat v jiném jazyce později), protože jsem nikde nenašel zdroj, který by řešil pohromadě veškerá úskalí tohoto řešení.
 Autor: Méďa – Software Architect
Autor: Méďa – Software Architect
Datum: 22.08.2021, 30 min.
› Požadavky na stránkování v JCS
Pro pochopení následujících odstavců vám v krátkosti představím, jaké máme interně na stránkování požadavky a sestavíme si tu nějakou testovací kolekci dat, vůči které si jednotlivá úskalí ukážeme.
REST API interface
Naše microservisy (dále jen MS) musí na svém REST API rozhraní pro stránkování implementovat podporu pomocí query parametrů v rámci volání kolekcí, které stránkování umožňují. Jedná se o parametry first, last, after, before, sort.
-
sort– objekt, který umožnuje klientovi specifikovat pomocí parametrůorderadirection, jak chce výsledky kolekce řaditfirst– počet dalších záznamů, které chceme získat (posílá se společně s cursoremafter)last– počet předchozích záznamů, které chceme získat (posílá se společně s cursorembefore)after– hodnota cursoru (base64 encoded)before– hodnota cursoru (base64 encoded)
Implementace vychází ze specifikace JSON API a GraphQL, proč místo jednoduchého parametru limit (nebo size) používáme first a last je z důvodu, aby si klient mohl při prvním volání říci, zda-li ho zajímají první, nebo naopak poslední záznamy.
Volání klienta pomocí cURLu, který chce získat první záznam z kolekce seřazené dle jména sestupně, by tedy vypadalo asi následovně:
curl -X GET \ -H "accept: application/json" \ "https://api.test/api/v1/persons?first=1&orderBy[0].order=personName&orderBy[0].direction=DESC"
Výsledek volání je JSON objekt, který má v sobě informace o stránkování a samotné záznamy. Struktura odpovědi stránkované kolekce má tedy u nás takovouto podobu
items[]– pole položek z kolekcenode– vlastní objekt dané položky kolekcecursor– hodnota cursoru pro konkrétní položku (tedy klient může použít pro stránkování jakýkoliv cursor)
pageInfohasNextPage– Informace, zda-li existují další záznamyhasPreviousPage– Informace, zda-li existují předchozí záznamystartCursor– v případě žehasPreviousPage = trueendCursor– v případě, žehasNextPage = true
Takže výsledek předchozího volání by vypadal nějak takto:
Testovací kolekce (MySQL)
Jako testovací kolekci dat jsem připravil jednoduchou tabulku Persons, která obsahuje jako primární klíč auto increment Id, jméno osoby a datum a čas jejího posledního přihlášení. Testovací data vypadají takto:
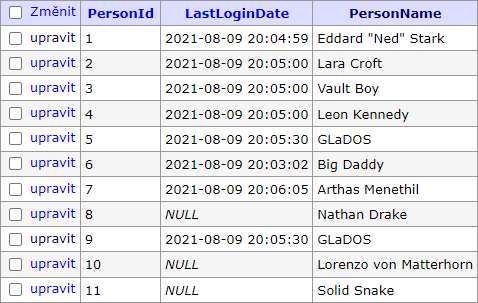
› Implementace – Je to jednoduché …… říkali
Základy
Požadavky na stránkování máme tedy vyjasněné a můžeme se vrhnout do vlastní implementace. Začneme tedy tím nejjednodušším příkladem, tedy že nedovolíme uživateli vybrat dle čeho chce řadit. Musíme tedy akorát zajistit, abychom výsledky řadili vždy dle sloupce s unikátními hodnotami, my pro to tedy použijeme sloupec PersonId, což je primární klíč a máme vystaráno. Implementace by tedy vypadala takto:
SELECT * FROM Persons ORDER BY PersonId ASC;
Tímto máme zaručeno, že budou výsledky vždycky ve správném pořadí a nemůže se nám tedy stát, že nám přibude doprostřed nějaký záznam, jelikož nový záznam dostane vyšší Id a zařadí se v tomto případě na konec.
Jak poznáme, zda-li existují další záznamy?
 U každé stránkované kolekce mám z povahy typu dat nastaven nějaký defaultní limit, pokud klient v požadavku nespecifikuje svůj vlastní (a taktéž samozřejmě i maximální povolený). Takže dejme tomu, že si klient řekne o prvních 5 záznamů. Jak tedy poznat, že existují další záznamy, abych mohl nazpět poslat správnou hodnotu
U každé stránkované kolekce mám z povahy typu dat nastaven nějaký defaultní limit, pokud klient v požadavku nespecifikuje svůj vlastní (a taktéž samozřejmě i maximální povolený). Takže dejme tomu, že si klient řekne o prvních 5 záznamů. Jak tedy poznat, že existují další záznamy, abych mohl nazpět poslat správnou hodnotu hasNextPage?
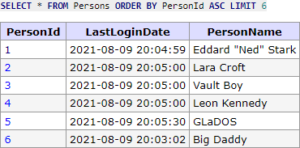
Na to existuje jednoduchý trik, do LIMITu přidáme o jeden záznam více, než klient (nebo default) vyžaduje, tím zjistíme, že existuje alespoň jeden další záznam a tento záznam samozřejmě z výsledků pro klienta odstraníme. Takže nově dotaz vypadá takto:
SELECT * FROM Persons ORDER BY PersonId ASC LIMIT 6;
Jelikož se jedná o získání dat bez cursoru, tak víme, že v tomto případě neexistují předchozí záznamy, tedy hodnotu hasPreviousPage nastavíme automaticky na false a nebudeme vracet startCursor.
Jaká data obsahuje cursor?
 Nyní stojíme před tím, co vlastně za data má obsahovat cursor. Záleží na vlastní implementaci, jak má formát vypadat, ale obecně potřebujete mít v cursoru data, která vám jednoznačně identifikují konkrétní záznam. Jedná se tedy mapování o data ze sloupců, pomocí kterých řadíme záznamy. Já jsem si zvolil formát JSON pole hodnot, kam si ukládám ve správném pořadí hodnoty, které potřebuji pro sestavení dalšího dotazu. Tedy v tomto případě potřebuji hodnotu
Nyní stojíme před tím, co vlastně za data má obsahovat cursor. Záleží na vlastní implementaci, jak má formát vypadat, ale obecně potřebujete mít v cursoru data, která vám jednoznačně identifikují konkrétní záznam. Jedná se tedy mapování o data ze sloupců, pomocí kterých řadíme záznamy. Já jsem si zvolil formát JSON pole hodnot, kam si ukládám ve správném pořadí hodnoty, které potřebuji pro sestavení dalšího dotazu. Tedy v tomto případě potřebuji hodnotu PersonId, kterou používám pro unikátní řazení záznamu. Cursor bych sestavil následovně:
$cursor = base64_encode((string)json_encode([(int)$personIdFromDb]));
což je hodnota WzVd, protože jako endCursor vracíme záznam s PersonId 5
Jak tedy vypadá následující dotaz na další záznamy?
 Klient obdržel v odpovědi 5 požadovaných záznamů, první s
Klient obdržel v odpovědi 5 požadovaných záznamů, první s PersonId 1 a poslední s PersonId 5, informaci, že existuje další stránka a hodnotu endCursor. Klient tedy sestaví následující dotaz, aby dostal dalších 5 záznamů.
curl -X GET \ -H "accept: application/json" \ "https://api.test/api/v1/persons?first=5&after=WzVd"
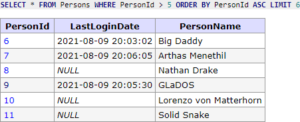
Na backend dostaneme požadavek na dalších 5 záznamů a hodnotu cursoru, od kterého záznamu chceme pokračovat. Jednoduše si rozparsujeme data cursoru (base64_decode(), json_decode()), čímž získáme hodnotu 5 a tu použijeme pro další dotaz následovně:
SELECT * FROM Persons WHERE PersonId > 5 ORDER BY PersonId ASC LIMIT 6;
 Vrátilo se nám opět více záznamů, než bylo požadováno, tedy víme, že existuje ještě následující stránka. A jelikož jsme obdrželi i samotný cursor, tak víme, že musí existovat i předchozí stránka. Nazpátek v tomto případě vracíme
Vrátilo se nám opět více záznamů, než bylo požadováno, tedy víme, že existuje ještě následující stránka. A jelikož jsme obdrželi i samotný cursor, tak víme, že musí existovat i předchozí stránka. Nazpátek v tomto případě vracíme hasNextPage = true, hasPreviousPage = true, startCursor = 'WzZd'(Id 6) a endCursor = 'WzEwXQ==' (Id 10).
Pokud by klient provedl ještě jedno volání, vrátili bychom už jen poslední 11. záznam, tím pádem bychom zjistili, že již neexistují žádné další záznamy a klient by se mohl jen vrátit k předchozím.
Jak je vidět. Na tom přeci není nic složitého ne?
› No jo, ale co když chci řadit podle jiných sloupců?
Princip stránkování se řazením dle primárního klíče už umíme, tak to pojďme rozšířit o možnost řazení dle jiného sloupce, přeci jen většinou nechceme vracet záznamy řazené dle primárního klíče, ale z povahy dat dle jiných atributů, například názvu nebo data vložení. Základ nám zůstane, na posledním místě řazení musí zůstat sloupec s unikátním záznamem, ale k tomu umožníme řadit ještě dle sloupce PersonName.
Tedy klient opět pošle požadavek na prvních 5 záznamů, ale nyní s požadavkem na řazení dle jména sestupně, tedy následovně:
curl -X GET \ -H "accept: application/json" \ "https://api.test/api/v1/persons?first=5&sort[0].order=personName&sort[0].direction=DESC"
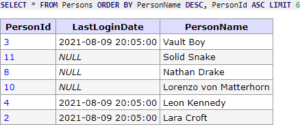 SQL dotaz bude vypadat podobně, jako při předchozím řazení, akorát na prvním místě bude řazení dle požadavku klienta a na druhém kvůli unikátnosti zůstane naše defaultní řazení dle Id.
SQL dotaz bude vypadat podobně, jako při předchozím řazení, akorát na prvním místě bude řazení dle požadavku klienta a na druhém kvůli unikátnosti zůstane naše defaultní řazení dle Id.
SELECT * FROM Persons ORDER BY PersonName DESC, PersonId ASC LIMIT 6;
Nyní potřebujeme rozšířit hodnoty našeho cursoru, jelikož máme 2 sloupce, podle kterých záznamy řadíme, přidáme do něj i hodnotu ze sloupce PersonName. Pro tento dotaz vracíme jako endCursor hodnotu WyJMZW9uIEtlbm5lZHkiLDRd, protože poslední vrácený záznam uživateli je s PersonId 4 (5 záznam v pořadí).
Sestavení cursoru jsem provedl takto:
$cursor = base64_encode(json_encode(["Leon Kennedy", 4]));
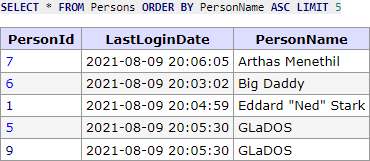 Proč musíme pro cursor používat obě hodnoty je z důvodu, že data ve sloupci
Proč musíme pro cursor používat obě hodnoty je z důvodu, že data ve sloupci PersonName nejsou unikátní a bez záznamu PersonId bychom nevěděli, od kterého záznamu máme pokračovat pro další stránkování.
Zde je vidět, že pokud bychom řadili dle jména vzestupně a nepoužili jako druhou možnost řazení dle PersonId, tak se nám vrátí na 4. a 5. místě záznam se stejným jménem a klidně může přibýt další.
Jak v tomto případě získat stránku s dalšími záznamy?
Klientovi jsme opět vrátili 5 záznamů a hodnotu cursoru pro požadavek na další stánku a můžeme se vrhnout na implementaci získání dalších záznamu, když mám v cursoru 2 hodnoty. Nezbytné je, že klient při stránkování nemění požadavky na řazení (o tom v pozdějších kapitolách), tedy se můžeme spolehnout, že hodnoty v cursoru sedí se sloupci, dle kterých řadíme data. Od klienta jsme nově obdrželi cursor, který obsahuje pro sloupec PersonName hodnotu Leon Kennedy a pro sloupec PersonId hodnotu 4. Zkusíme nyní upravit náš SQL dotaz následovně:
SELECT * FROM Persons WHERE PersonName < "Leon Kennedy" OR (PersonName = "Leon Kennedy" AND PersonId > 4) ORDER BY PersonName DESC, PersonId ASC LIMIT 6
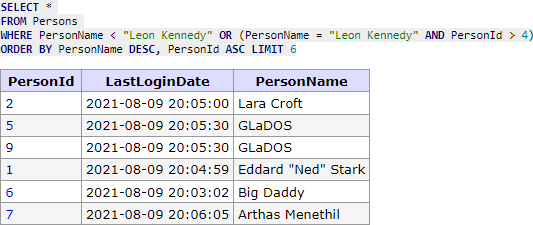 Teď si vysvětlíme tu podmínku. Jelikož řadíme dle
Teď si vysvětlíme tu podmínku. Jelikož řadíme dle PersonName sestupně, tak očekáváme, že následující hodnoty budou menší, tedy volíme operátor <. Ale jelikož víme, že sloupec PersonName není unikátní, tak v případě, že bychom narazili na záznam se stejným jménem, tak použijeme řazení dle PersonId, které je již unikátní. Je vidět, že i vazba operátoru pro porovnání se řídí tím, jakým způsobem data řadíme, tedy pro DESC používáme < a pro ASC používáme >.
› Chci víc!
 Dobrá, dobrá, chápu, i řazení pomocí 2 sloupců nemusí být terno. Tak si ukážeme, že je vlastně jedno, pomoci kolika sloupců umožním řadit, jelikož podmínka už bude vždy se stejnou logikou. Rozšíříme tedy možnost řazení v našich testovacích datech na 3 sloupce, například dle data posledního přihlášení, poté dle jména a pak pomocí našeho primárního klíče.
Dobrá, dobrá, chápu, i řazení pomocí 2 sloupců nemusí být terno. Tak si ukážeme, že je vlastně jedno, pomoci kolika sloupců umožním řadit, jelikož podmínka už bude vždy se stejnou logikou. Rozšíříme tedy možnost řazení v našich testovacích datech na 3 sloupce, například dle data posledního přihlášení, poté dle jména a pak pomocí našeho primárního klíče.
Základní dotaz pro první set výsledků by vypadal takto:
SELECT * FROM Persons ORDER BY LastLoginDate ASC, PersonName DESC, PersonId ASC LIMIT 6;
Nic složitého, úplně stejně, jako v předchozím případě rozšíříme náš cursor o další hodnotu, tedy nově by se skládal z dat
$cursor = base64_encode(json_encode(['2021-08-09 20:04:59', 'Eddard "Ned" Stark', 1]));
tedy hodnoty WyIyMDIxLTA4LTA5IDIwOjA0OjU5IiwiRWRkYXJkIFwiTmVkXCIgU3RhcmsiLDFd.
A jak bude vypadat vyhodnocení při požadavku na další výsledky? Stačí nám jen trošku upravit SQL, kde si již všimnete stejného vzorce, který je aplikovatelný na neomezený počet způsobů řazení (aspoň co vám engine dovolí 😅).
SELECT * FROM Persons WHERE LastLoginDate > "2021-08-09 20:04:59" OR (LastLoginDate = "2021-08-09 20:04:59" AND PersonName < "Eddard \"Ned\" Stark") OR (LastLoginDate = "2021-08-09 20:04:59" AND PersonName = "Eddard \"Ned\" Stark" AND PersonId > 1) ORDER BY LastLoginDate ASC, PersonName DESC, PersonId ASC;
Je vidět, že se pouze rozšiřuje počet OR podmínek, a musí se počítat s variantou, kdy všechny ne-unikátní hodnoty mohou být v DB vícekrát, až skončíme u porovnání s naším unikátním záznamem, jako je vidět například u uživatelky GLaDOS, která má stejný čas posledního přihlášení.

> Říkal jsi něco o získání posledních záznamů?
 Díky za zeptání, jasně, umožňujeme klientovi si říci, že chce dostat poslední záznamy z dané kolekce. Má to nějaký vliv na implementaci stránkování? Jak tyto záznamy dostanu z DB? A co na to Jan Tleskač?
Díky za zeptání, jasně, umožňujeme klientovi si říci, že chce dostat poslední záznamy z dané kolekce. Má to nějaký vliv na implementaci stránkování? Jak tyto záznamy dostanu z DB? A co na to Jan Tleskač?
Začněme opět s tím nejjednodušším příkladem, tedy že klient chce dostat 5 posledních záznamů z naší testovací kolekce uživatelů. Pro něj je to jednoduché. V query parametru místo first použije last a tím pro něj práce končí. Co to ale znamená pro nás?
Pracujeme se stejnou logikou, že primárně řadíme data dle PersonId vzestupně, tedy kolekce v DB vypadá tak, jak je na obrázku níže.

Klient si řekl, že chce posledních 5 záznamů (chce dostat záznamy od PersonId 7 až po PersonId 11).
Získání těchto záznamů provedeme celkem jednoduše tak, že změníme reverzně způsob řazení. Místo ASC použijeme DESC a následně aplikujeme náš trik s limitem +1. SQL dotaz tedy bude vypadat následovně:
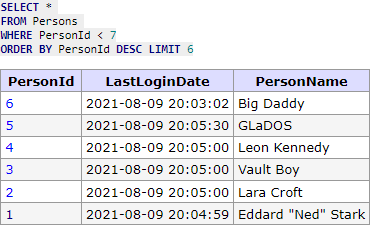
SELECT * FROM Persons ORDER BY PersonId DESC LIMIT 6;
čímž dostanu záznamy viz obrázek.
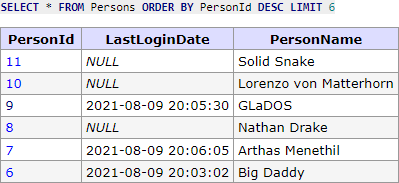
Nyní pracujeme v reverzním módu. To, že dostáváme více záznamů, než si klient řekl, nám nastavuje hodnotu hasPreviousPage a naopak hasNextPage bude mít nastaveno false (jelikož se jedná o první dotaz bez cursoru a vracíme poslední záznamy). 6. záznam tedy opět odstraňujeme ale co je důležité, musíme nyní aplikačně změnit pořadí záznamů, jelikož klient je očekává ve správném pořadí, tedy v pořadí PersonId následovně: 7, 8, 9, 10, 11. Uděláme aplikačně jen něco jako:
$response = array_reverse($response);
Tadá🥳, klient dostává svá požadovaná data (nastavování hodnot cursorů a další funguje naprosto stejně)
A jak získám předchozí záznamy?
Teď, když umíme pracovat v reverzním módu, tak může klient zasílat požadavky s cursorem before, tedy říkat si o předchozí záznamy. Tím, že si říká o data s cursorem before víme, že budeme pracovat v reverzním módu a vše, co musíme udělat je jen otočit logiku řazení a změnit hodnoty operátorů pro porovnání. S daty z předchozího volání dostane klient jako startCursor (hodnota pro cursor before) hodnotu PersonId 7, kterou mi zpracujeme v SQL dotazu následovně:
SELECT * FROM Persons WHERE PersonId < 7 ORDER BY PersonId DESC LIMIT 6;
Jak je vidět, tak jsme změnili opět způsob řazení na DESC a tím jsme museli změnit i operátor < pro porovnání. S výsledky opět provedeme to samé co před tím, tedy pokud existuje, tak ořízneme nechtěné záznamy nad limitem a uděláme revers výsledků.
Funguje to i pro řazení dle více sloupců?
Dobrá otázka. Samozřejmě tento postup je aplikovatelný na řazení dle vícero sloupců. Jediné, co si musíme zapamatovat, je že vezmeme původní řazení a u každého provedeme reverzně způsob řazení a změnu vyhodnocení. Pokud chce uživatel získat data seřazená pomocí LastLoginDate ASC, PersonName DESC, PersonId ASC tak v reverzním módu budeme hledat jako LastLoginDate DESC, PersonName ASC, PersonId DESC
› A co jsou to ty NULL hodnoty?
 Dobře, máte mě. Tak jednoduché to zcela není. Zatajil jsem vám na začátku pro zjednodušení záměrně jednu věc, která do všeho trošku hází vidle, a to je situace, kdy řadíte pomocí sloupce, ve kterém mohou být
Dobře, máte mě. Tak jednoduché to zcela není. Zatajil jsem vám na začátku pro zjednodušení záměrně jednu věc, která do všeho trošku hází vidle, a to je situace, kdy řadíte pomocí sloupce, ve kterém mohou být NULL hodnoty. Nebojte, nemažte ještě žádný kód a neutíkejte, stačí nám troška refaktoringu a pár ifů a poradíme si i s tímhle.
Co přesně to pro nás znamená a co budeme muset dělat jinak. K tomu budeme potřebovat nejprve vědět, jak se chovají různé DB enginy k NULL hodnotám. Pro to, aby nám vše správně fungovalo, totiž potřebujeme, aby byly NULL záznamy vždy buď jako první, nebo jako poslední (a potřebujeme kvůli reverznímu módu obě varianty). Kdo pracuje s PostgreSQL, tak ten je na tom o trošku lépe, jelikož umožňuje řídit chování pomocí NULLS FIRST nebo NULLS LAST viz dokumentace.
Můj refaktorovaný projekt používá bohužel MySQL, která ani ve verzi 8 nepodporuje nějakým nastavením měnit pořadí NULL hodnot, a tak jen v dokumentaci stroze píše, že pokud řadíme vzestupně, jsou NULL hodnoty jako první, pokud sestupně, jsou jako poslední.
When using ORDER BY, NULL values are presented first, or last if you specify DESC to sort in descending order.
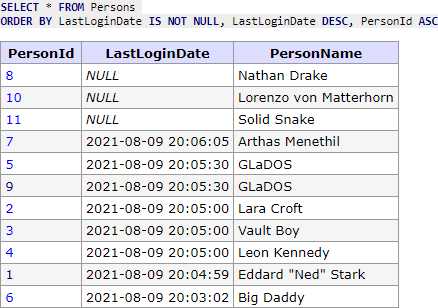
Naštěstí lze využít chování MySQL a potřebného chování docílit tak, že u sloupců, kde mohou být i NULL záznamy, řídíme jejich pozici následujícím způsobem. Chceme-li, aby NULL hodnoty byly poslední, použijeme syntaxi ORDER BY LastLoginDate IS NULL, LastLoginDate ASC a obráceně jen změnou podmínky ORDER BY LastLoginDate IS NOT NULL, LastLoginDate ASC. Zde pro ukázku srovnání, že to opravdu funguje bez ohledu na směr řazení.

Obsah dat v cursoru zůstává stejný, tedy je-li hodnota NULL, bude i v cursoru. Například:
$cursor = base64_encode(json_encode([null, 'Lorenzo von Matterhorn', 10]));
A jak bude vypadat vyhodnocení dle dat z cursoru?
Vlastně to není žádná vyšší dívčí, akorát si nevystačíme s operátory >, < a =, ale budeme potřebovat používat IS NULL, IS NOT NULL. Tím, že umíme řídit to, zda se NULL hodnoty vyskytují vždy jako první, nebo jako poslední, můžeme pracovat jednoduše s podmínkami dle toho, zda-li aktuální hodnota cursoru je NULL nebo není. Pokud totiž máme nastaveny NULL záznamy jako první a aktuální hodnota cursoru není NULL, tak víme, že pro získání dalších záznamů nesmějí být NULL a získání předchozích musí být menší, nebo NULL.
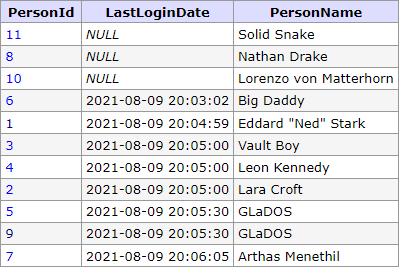
Nejlepší je si to ukázat zase na nějakém příkladu. Dejme tomu, že řadíme dle LastLoginDate DESC a PersonId ASC, NULL máme nastaveny jako první a chceme získat první 2 záznamy. (Na obrázku jsou záznamy všechny, aby bylo jednodušší si představit další průchody.)
Klient chtěl 2 záznamy, takže dostane Id 8 a 10, a záznam s Id 10 bude použit jako endCursor s hodnotami:
$cursor = base64_encode(json_encode([null, 10]));
Další 2 záznamy získáme následující podmínkou:
SELECT * FROM Persons WHERE LastLoginDate IS NOT NULL OR (LastLoginDate IS NULL AND PersonId > 10) ORDER BY LastLoginDate IS NOT NULL, LastLoginDate DESC, PersonId ASC
Z ukázky je zřejmě, že je to naprosto stejný princip, akorát místo porovnávání <, > a = se používá porovnání NULL hodnot. Tedy tato podmínka správně vrátí následující záznamy:
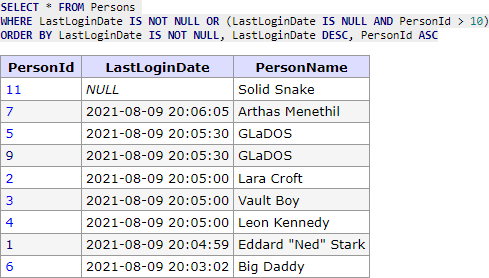
Nyní klient dostane jako poslední záznam s Id 7, takže se nám další podmínka změní na následující:
SELECT * FROM Persons WHERE LastLoginDate < "2021-08-09 20:06:05" OR (LastLoginDate = "2021-08-09 20:06:05" AND PersonId > 7) ORDER BY LastLoginDate IS NOT NULL, LastLoginDate DESC, PersonId ASC
Všimněte si, že tím, že jsme se dostali za všechny NULL záznamy, tak už porovnáváme hodnoty stejně, jako jsme to dělali dříve.
Naprosto stejně se budou vyhodnocovat i záznamy v reverzním režimu, nebo pokud budeme mít nastaveny NULL hodnoty jako poslední, je to jen o hraní si s tím, jakou podmínku pro danou situaci aplikujeme.

› UNION ALL ….
Při implementaci jsem narazil ještě na potřebu řešit stránkování u dotazů spojených pomocí UNIONu (získáváme historické eventy z různých tabulek). Naštěstí díky implementaci předchozích potřeb to bylo celkem jednoduché, hodnoty cursoru se prostě předaly do každého ze selectu, tedy pak výsledný dotaz vypadal nějak podobně:
SELECT *, GetComponentNameFromHistory(`E`.`CloudComponentId`, `EventTime`) `ComponentName` FROM ( SELECT `DE`.`DeviceEventId` `EventId`, `DE`.`DeviceEventTime` `EventTime` FROM `DeviceEvent` `DE` WHERE `DE`.`ObjectId` = 12345 AND (`DE`.`DeviceEventTime` < "2021-08-31 21:26:25" OR (`DE`.`DeviceEventTime` = "2021-08-31 21:26:25" AND `DE`.`DeviceEventId` < "95ba3b2f-01c0-4d2f-8965-3f82ef30cbfe")) UNION ALL SELECT `CE`.`CloudEventId` `EventId`, `CE`.`CloudEventTime` `EventTime` FROM `CloudEvent` `CE` WHERE `CE`.`ObjectId` = 12345 AND (`CE`.`CloudEventTime` < "2021-08-31 21:26:25" OR (`CE`.`CloudEventTime` = "2021-08-31 21:26:25" AND `CE`.`CloudEventId` < "95ba3b2f-01c0-4d2f-8965-3f82ef30cbfe")) ) E ORDER BY `EventTime` DESC, `EventId` DESC
› Důvěřuj, ale prověřuj
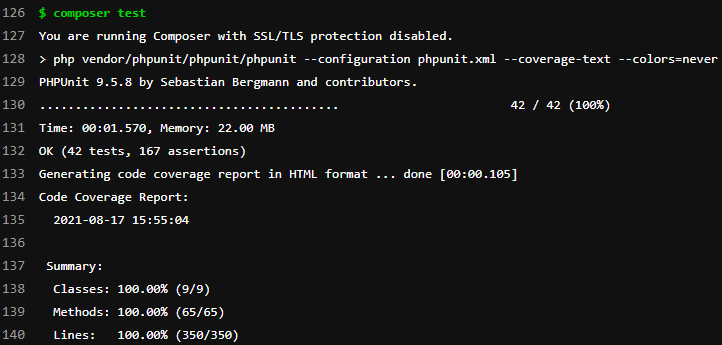
Jako poslední stačilo napsat k celé knihovně testy, což bylo stejně tak časově náročné, jako celá implementace, protože právě díky testům jsem nacházel nejrůznější krajní případy, kdy bylo potřeba přidat další level aplikační logiky. V rámci knihovny je pár unit testů, ale hlavně integrační testy opřené proti docker MySQL, kde v rámci setupu každého testu je vytvoření DB a naplnění těmito testovacími daty.
Určitě je potřeba validovat data od klienta, tedy kombinaci parametrů a obsah cursorů (přeci jen jsou to data od uživatele). Je možné si do struktury cursorů přidat k hodnotám klidně i názvy sloupců, kterých se hodnoty týkají a ty pak validovat oproti aktuálně vybraným sloupcům z dotazu (abychom detekovali, že uživatel poslal cursor a přitom změnil způsob řazení).
Celá knihovna mi trvala včetně testů kolem 16 hodin, kde většina času byl refaktoring již jednou napsaného při objevení dalšího krajního případu. Takže doufám, že třeba tento článek pomůže alespoň jednomu dalšímu vývojáři 👋, aby se z toho nezbláznil.